ファイルからデータを取得する
Kotlin Notebookは、Kotlin DataFrameライブラリと組み合わせることで、非構造化データと構造化データの両方を扱うことができます。この組み合わせにより、TXTファイルにあるデータのような非構造化データを、構造化されたデータセットに柔軟に変換できます。
データ変換には、add、split、convert、parseなどのメソッドを使用できます。さらに、このツールセットを使用すると、CSV、JSON、XLS、XLSX、Apache Arrowなどのさまざまな構造化ファイル形式のデータを取得および操作できます。
このガイドでは、複数の例を通して、データを取得、改良、および処理する方法を学ぶことができます。
始める前に
-
最新バージョンのIntelliJ IDEA Ultimateをダウンロードしてインストールします。
-
IntelliJ IDEAにKotlin Notebook pluginをインストールします。
または、IntelliJ IDEA内のSettings | Plugins | MarketplaceからKotlin Notebook pluginにアクセスします。
-
File | New | Kotlin Notebookを選択して、新しいKotlin Notebookを作成します。
-
Kotlin Notebookで、次のコマンドを実行してKotlin DataFrameライブラリをインポートします。
%use dataframe
ファイルからデータを取得する
Kotlin Notebookでファイルからデータを取得するには:
-
Kotlin Notebookファイル(
.ipynb)を開きます。 -
Notebookの先頭にあるコードセルに
%use dataframeを追加して、Kotlin DataFrameライブラリをインポートします。Kotlin DataFrameライブラリに依存する他のコードセルを実行する前に、
%use dataframe行を含むコードセルを実行してください。 -
Kotlin DataFrameライブラリの
.read()関数を使用して、データを取得します。たとえば、CSVファイルを読み取るには、DataFrame.read("example.csv")を使用します。
.read()関数は、ファイル拡張子とコンテンツに基づいて入力形式を自動的に検出します。delimiter = ';'で区切り文字を指定するなど、他の引数を追加して関数をカスタマイズすることもできます。
追加のファイル形式とさまざまな読み取り関数の包括的な概要については、Kotlin DataFrameライブラリのドキュメントを参照してください。
データを表示する
Notebookにデータを取り込んだら、簡単に変数に格納し、コードセルで次を実行してアクセスできます。
val dfJson = DataFrame.read("jsonFile.json")
dfJson
このコードは、CSV、JSON、XLS、XLSX、Apache Arrowなど、選択したファイルのデータを表示します。
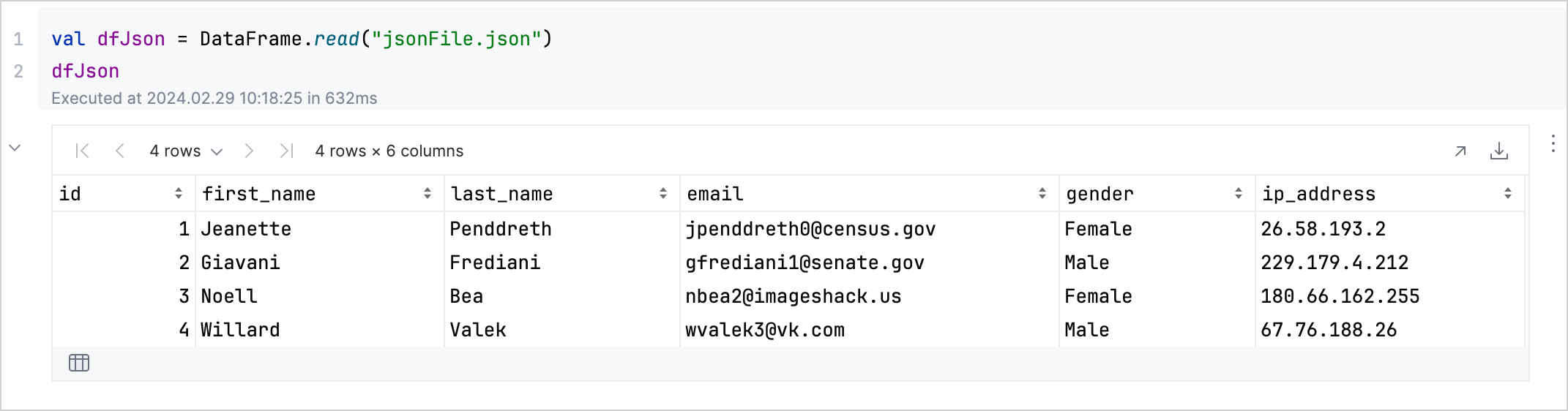
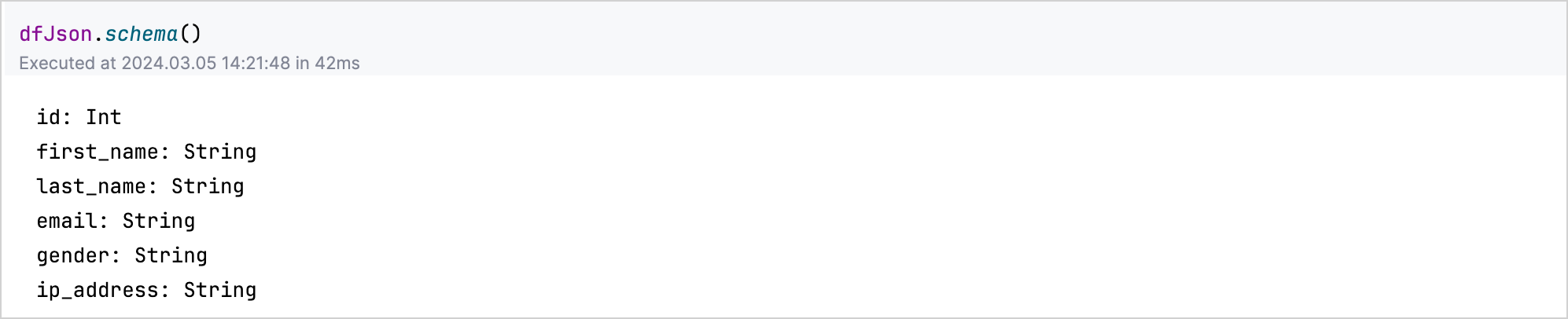
データの構造またはスキーマに関する洞察を得るには、DataFrame変数に.schema()関数を適用します。たとえば、dfJson.schema()は、JSONデータセット内の各列の型をリストします。
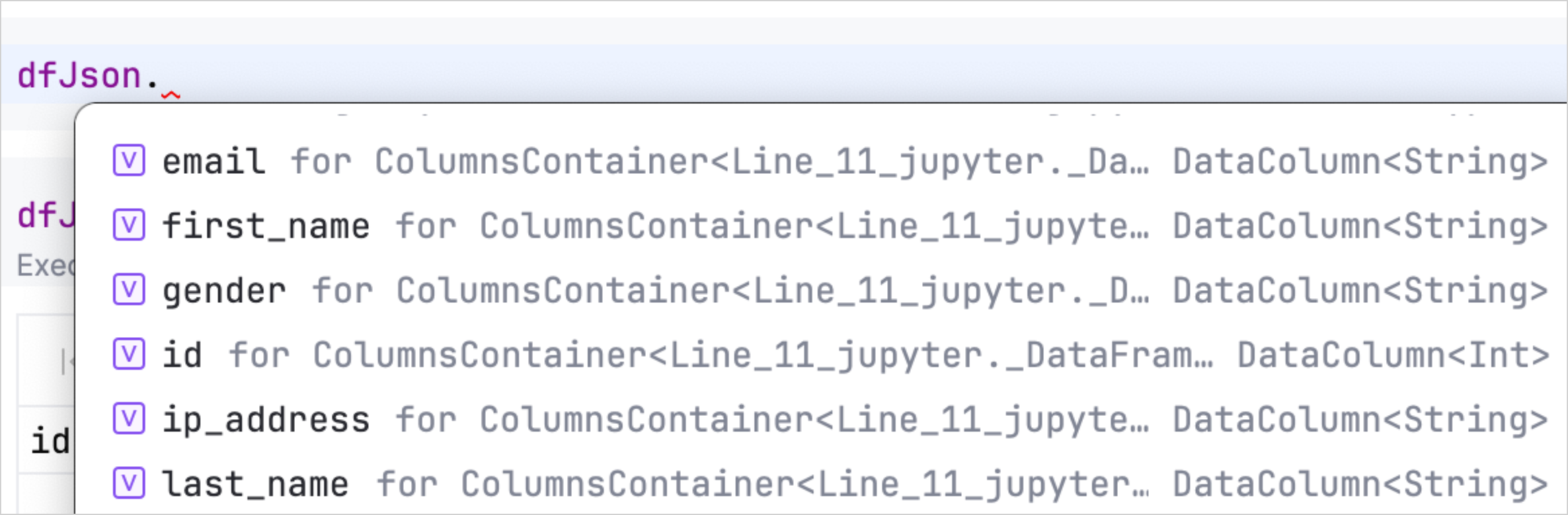
Kotlin Notebookのオートコンプリート機能を使用して、DataFrameのプロパティにすばやくアクセスして操作することもできます。データをロードした後、DataFrame変数の後にドットを入力するだけで、使用可能な列とその型のリストが表示されます。
データを改良する
Kotlin DataFrameライブラリで利用可能なデータセットを改良するためのさまざまな操作の中でも、主な例としては、grouping、filtering、updating、および新しい列の追加があります。これらの関数はデータ分析に不可欠であり、データを効果的に整理、クリーンアップ、および変換できます。
データに映画のタイトルと対応する公開年が同じセルに含まれている例を見てみましょう。目標は、分析を容易にするためにこのデータセットを改良することです。
-
.read()関数を使用して、データをNotebookにロードします。この例では、movies.csvという名前のCSVファイルからデータを読み取り、moviesというDataFrameを作成します。val movies = DataFrame.read("movies.csv") -
正規表現を使用して映画のタイトルから公開年を抽出し、新しい列として追加します。
val moviesWithYear = movies
.add("year") {
"\\d{4}".toRegex()
.findAll(title)
.lastOrNull()
?.value
?.toInt()
?: -1
} -
各タイトルから公開年を削除して、映画のタイトルを変更します。これにより、タイトルの一貫性が保たれます。
val moviesTitle = moviesWithYear
.update("title") {
"\\s*\\(\\d{4}\\)\\s*$".toRegex().replace(title, "")
} -
filterメソッドを使用して、特定のデータに焦点を当てます。この場合、データセットは、1996年以降に公開された映画に焦点を当てるようにフィルタリングされています。val moviesNew = moviesWithYear.filter { year >= 1996 }
moviesNew
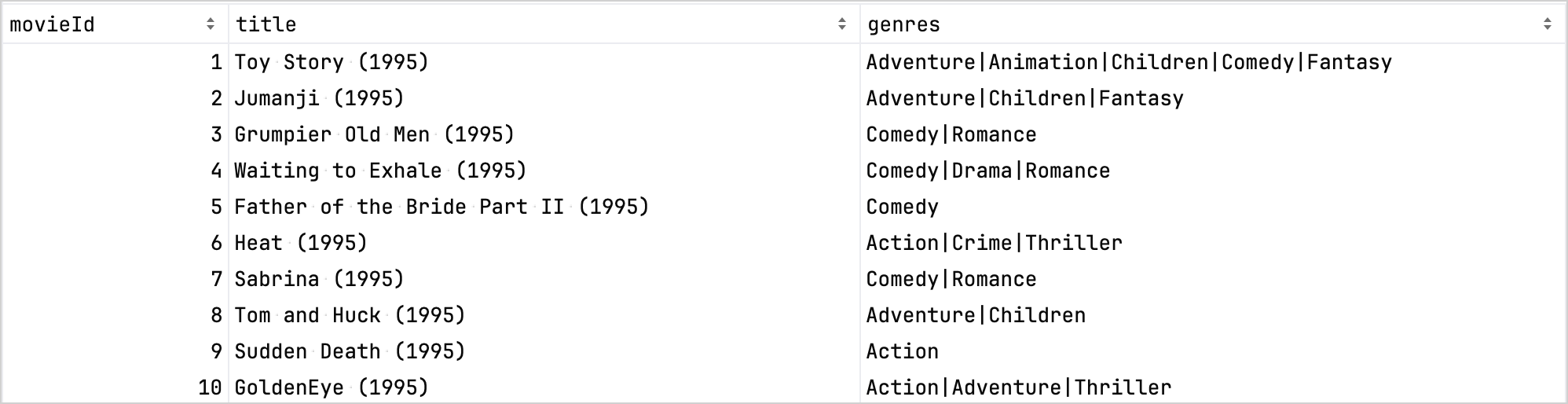
比較のために、改良前のデータセットを次に示します。
改良されたデータセット:
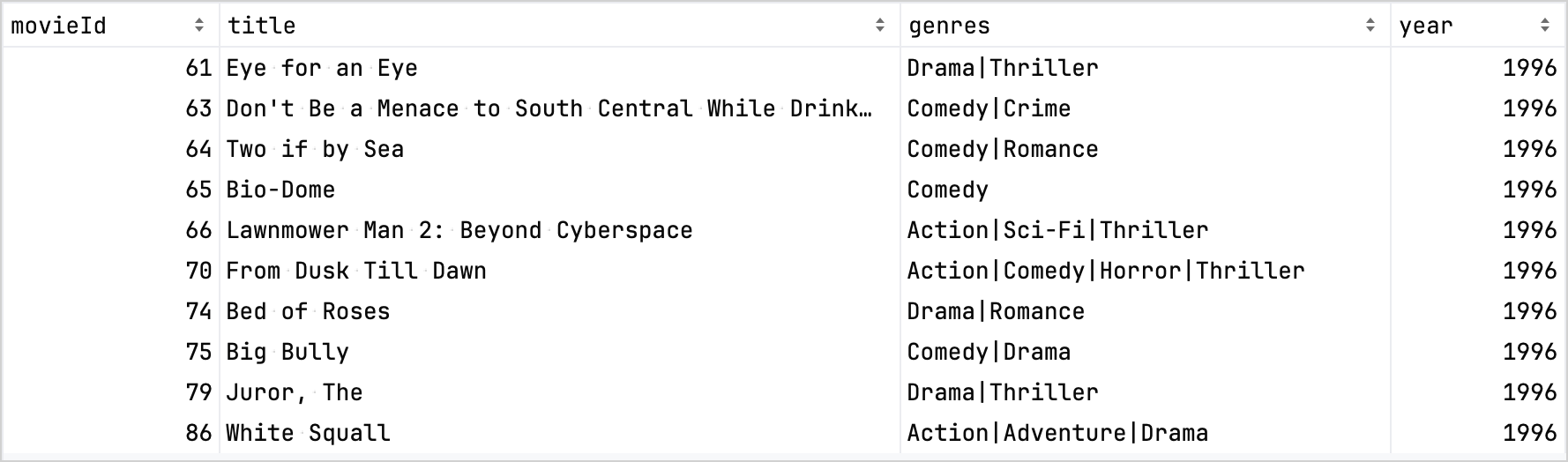
これは、Kotlin DataFrameライブラリのadd、update、およびfilterのようなメソッドを使用して、Kotlinでデータを効果的に改良および分析する方法の実用的なデモンストレーションです。
追加のユースケースと詳細な例については、Kotlin Dataframeの例を参照してください。
DataFrameを保存する
Kotlin DataFrameライブラリを使用してKotlin Notebookでデータを改良した後、処理されたデータを簡単にエクスポートできます。この目的のために、さまざまな.write()関数を利用できます。これらの関数は、CSV、JSON、XLS、XLSX、Apache Arrow、さらにはHTMLテーブルなど、複数の形式での保存をサポートしています。これは、調査結果の共有、レポートの作成、またはデータを利用してさらに分析する場合に特に役立ちます。
DataFrameをフィルタリングし、列を削除し、改良されたデータをJSONファイルに保存し、HTMLテーブルをブラウザで開く方法は次のとおりです。
-
Kotlin Notebookで、
.read()関数を使用して、movies.csvという名前のファイルをmoviesDfというDataFrameにロードします。val moviesDf = DataFrame.read("movies.csv") -
.filterメソッドを使用して、DataFrameをフィルタリングして、「Action」ジャンルに属する映画のみを含めます。val actionMoviesDf = moviesDf.filter { genres.equals("Action") } -
.removeを使用して、DataFrameからmovieId列を削除します。val refinedMoviesDf = actionMoviesDf.remove { movieId }
refinedMoviesDf -
Kotlin DataFrameライブラリには、さまざまな形式でデータを保存するためのさまざまな書き込み関数が用意されています。この例では、
.writeJson()関数を使用して、変更されたmovies.csvをJSONファイルとして保存します。refinedMoviesDf.writeJson("movies.json") -
.toStandaloneHTML()関数を使用して、DataFrameをスタンドアロンのHTMLテーブルに変換し、デフォルトのWebブラウザで開きます。refinedMoviesDf.toStandaloneHTML(DisplayConfiguration(rowsLimit = null)).openInBrowser()
次のステップ
- Kandyライブラリを使用したデータの可視化について調べる
- Kandyを使用したKotlin Notebookでのデータの可視化で、データの可視化に関する追加情報を探す
- Kotlinでのデータサイエンスと分析に利用できるツールとリソースの包括的な概要については、データ分析用のKotlinおよびJavaライブラリを参照してください