파일에서 데이터 검색
Kotlin Notebook은 Kotlin DataFrame 라이브러리와 결합되어 비정형 데이터와 정형 데이터 모두를 사용할 수 있도록 지원합니다. 이러한 조합은 TXT 파일에서 찾은 데이터와 같은 비정형 데이터를 정형 데이터 세트로 변환할 수 있는 유연성을 제공합니다.
데이터 변환을 위해 add, split,
convert 및 parse와 같은 메서드를 사용할 수 있습니다. 또한 이 툴셋을 사용하면 CSV, JSON, XLS, XLSX 및 Apache Arrow를 포함한 다양한 정형 파일 형식에서 데이터를 검색하고 조작할 수 있습니다.
이 가이드에서는 여러 예제를 통해 데이터를 검색, 구체화 및 처리하는 방법을 알아볼 수 있습니다.
시작하기 전에
-
최신 버전의 IntelliJ IDEA Ultimate을 다운로드하여 설치합니다.
-
IntelliJ IDEA에 Kotlin Notebook plugin을 설치합니다.
또는 IntelliJ IDEA 내에서 Settings | Plugins | Marketplace에서 Kotlin Notebook 플러그인에 액세스합니다.
-
File | New | Kotlin Notebook을 선택하여 새 Kotlin Notebook을 만듭니다.
-
Kotlin Notebook에서 다음 명령을 실행하여 Kotlin DataFrame 라이브러리를 가져옵니다.
%use dataframe
파일에서 데이터 검색
Kotlin Notebook에서 파일에서 데이터를 검색하려면 다음을 수행하십시오.
-
Kotlin Notebook 파일(
.ipynb)을 엽니다. -
노트북 시작 부분에 있는 코드 셀에
%use dataframe을 추가하여 Kotlin DataFrame 라이브러리를 가져옵니다.Kotlin DataFrame 라이브러리를 사용하는 다른 코드 셀을 실행하기 전에
%use dataframe줄이 있는 코드 셀을 실행해야 합니다. -
Kotlin DataFrame 라이브러리에서
.read()함수를 사용하여 데이터를 검색합니다. 예를 들어 CSV 파일을 읽으려면DataFrame.read("example.csv")를 사용합니다.
.read() 함수는 파일 확장자 및 콘텐츠를 기반으로 입력 형식을 자동으로 감지합니다. delimiter = ';'로 구분 기호를 지정하는 등 다른 인수를 추가하여 함수를 사용자 지정할 수도 있습니다.
추가 파일 형식과 다양한 읽기 함수에 대한 포괄적인 개요는 Kotlin DataFrame library documentation을 참조하십시오.
데이터 표시
노트북에 데이터를 저장한 후 코드 셀에서 다음을 실행하여 변수에 쉽게 저장하고 액세스할 수 있습니다.
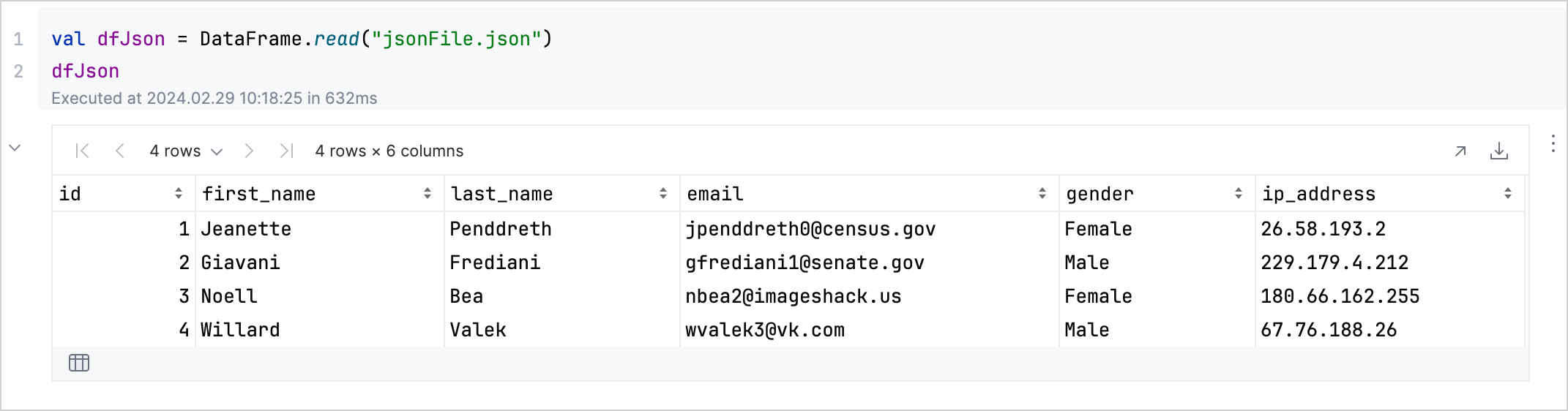
val dfJson = DataFrame.read("jsonFile.json")
dfJson
이 코드는 CSV, JSON, XLS, XLSX 또는 Apache Arrow와 같은 선택한 파일의 데이터를 표시합니다.
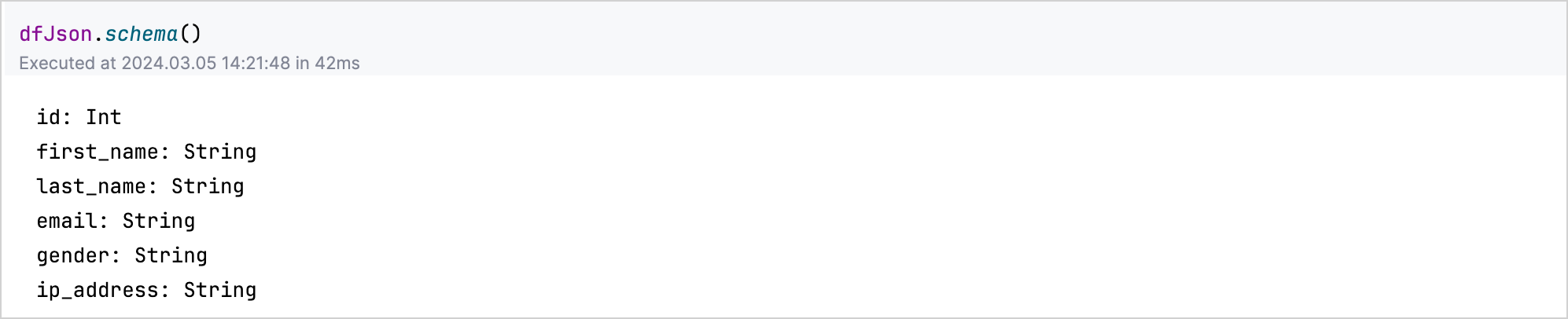
데이터의 구조나 스키마에 대한 통찰력을 얻으려면 DataFrame 변수에 .schema() 함수를 적용합니다. 예를 들어 dfJson.schema()는 JSON 데이터 세트의 각 열 유형을 나열합니다.
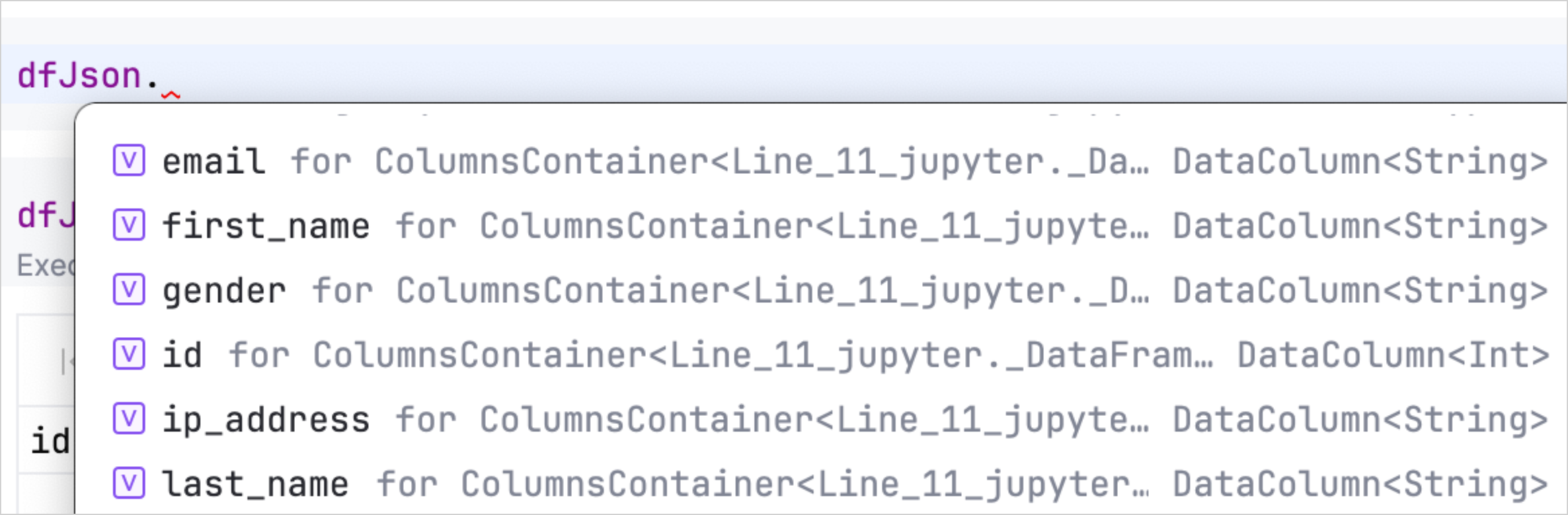
Kotlin Notebook의 자동 완성 기능을 사용하여 DataFrame의 속성에 빠르게 액세스하고 조작할 수도 있습니다. 데이터를 로드한 후 DataFrame 변수를 입력하고 마침표를 입력하면 사용 가능한 열과 해당 유형 목록이 표시됩니다.
데이터 구체화
데이터 세트를 구체화하기 위해 Kotlin DataFrame 라이브러리에서 사용할 수 있는 다양한 작업 중에서 주요 예로는 grouping, filtering, updating 및 adding new columns이 있습니다. 이러한 함수는 데이터 분석에 필수적이며 데이터를 효과적으로 구성, 정리 및 변환할 수 있습니다.
데이터에 영화 제목과 해당 출시 연도가 동일한 셀에 포함된 예제를 살펴보겠습니다. 목표는 더 쉬운 분석을 위해 이 데이터 세트를 구체화하는 것입니다.
-
.read()함수를 사용하여 데이터를 노트북에 로드합니다. 이 예에서는movies.csv라는 CSV 파일에서 데이터를 읽고movies라는 DataFrame을 만듭니다.val movies = DataFrame.read("movies.csv") -
정규식을 사용하여 영화 제목에서 출시 연도를 추출하고 새 열로 추가합니다.
val moviesWithYear = movies
.add("year") {
"\\d{4}".toRegex()
.findAll(title)
.lastOrNull()
?.value
?.toInt()
?: -1
} -
각 제목에서 출시 연도를 제거하여 영화 제목을 수정합니다. 이렇게 하면 제목이 일관성을 위해 정리됩니다.
val moviesTitle = moviesWithYear
.update("title") {
"\\s*\\(\\d{4}\\)\\s*$".toRegex().replace(title, "")
} -
filter메서드를 사용하여 특정 데이터에 집중합니다. 이 경우 데이터 세트는 1996년 이후에 출시된 영화에 집중하도록 필터링됩니다.val moviesNew = moviesWithYear.filter { year >= 1996 }
moviesNew
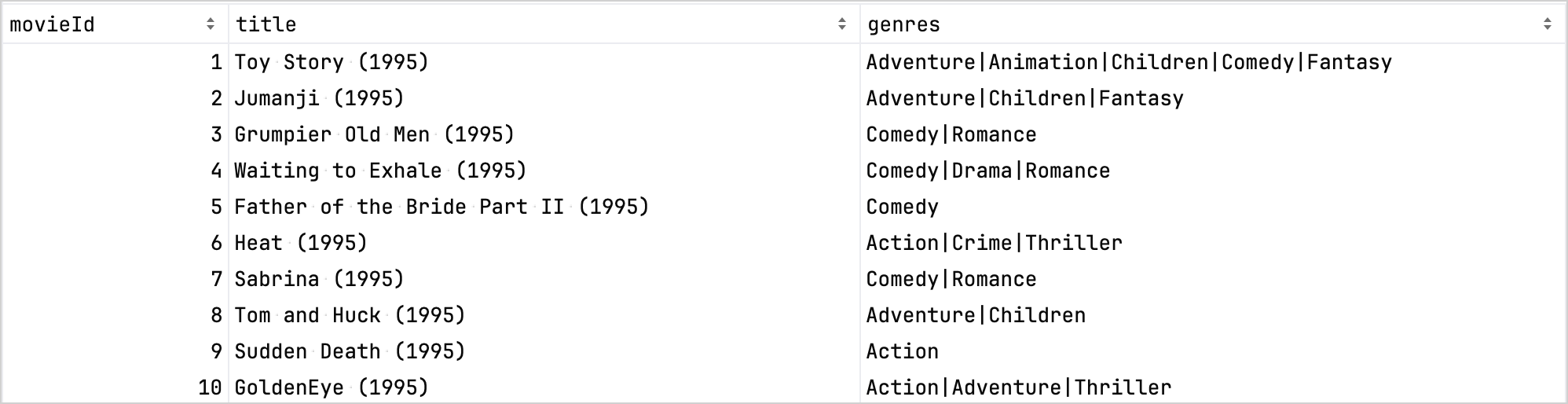
비교를 위해 다음은 구체화 전의 데이터 세트입니다.
구체화된 데이터 세트:
이것은 Kotlin에서 add, update 및 filter와 같은 Kotlin DataFrame 라이브러리의 메서드를 사용하여 데이터를 효과적으로 구체화하고 분석하는 방법을 보여주는 실제 데모입니다.
추가 사용 사례 및 자세한 예는 Examples of Kotlin Dataframe을 참조하십시오.
DataFrame 저장
Kotlin DataFrame 라이브러리를 사용하여 Kotlin Notebook에서 데이터를 구체화한 후 처리된 데이터를 쉽게 내보낼 수 있습니다. 이 목적을 위해 다양한 .write() 함수를 활용할 수 있으며, CSV, JSON, XLS, XLSX, Apache Arrow는 물론 HTML 테이블까지 다양한 형식으로 저장을 지원합니다. 이는 결과 공유, 보고서 생성 또는 추가 분석을 위해 데이터를 사용할 수 있도록 하는 데 특히 유용할 수 있습니다.
다음은 DataFrame을 필터링하고, 열을 제거하고, 구체화된 데이터를 JSON 파일에 저장하고, HTML 테이블을 브라우저에서 여는 방법입니다.
-
Kotlin Notebook에서
.read()함수를 사용하여movies.csv라는 파일을moviesDf라는 DataFrame에 로드합니다.val moviesDf = DataFrame.read("movies.csv") -
.filter메서드를 사용하여 "Action" 장르에 속하는 영화만 포함하도록 DataFrame을 필터링합니다.val actionMoviesDf = moviesDf.filter { genres.equals("Action") } -
.remove를 사용하여 DataFrame에서movieId열을 제거합니다.val refinedMoviesDf = actionMoviesDf.remove { movieId }
refinedMoviesDf -
Kotlin DataFrame 라이브러리는 다양한 형식으로 데이터를 저장하기 위한 다양한 쓰기 함수를 제공합니다. 이 예에서는
.writeJson()함수를 사용하여 수정된movies.csv를 JSON 파일로 저장합니다.refinedMoviesDf.writeJson("movies.json") -
.toStandaloneHTML()함수를 사용하여 DataFrame을 독립 실행형 HTML 테이블로 변환하고 기본 웹 브라우저에서 엽니다.refinedMoviesDf.toStandaloneHTML(DisplayConfiguration(rowsLimit = null)).openInBrowser()
다음 단계
- Kandy library를 사용하여 데이터 시각화 탐색
- Data visualization in Kotlin Notebook with Kandy에서 데이터 시각화에 대한 추가 정보 찾기
- Kotlin의 데이터 과학 및 분석에 사용할 수 있는 도구 및 리소스에 대한 광범위한 개요는 Kotlin and Java libraries for data analysis를 참조하십시오.