WebソースおよびAPIからデータを取得する
Kotlin Notebook は、さまざまな Web ソースや API からのデータへのアクセスと操作のための強力なプラットフォームを提供します。 明確にするためにすべてのステップを視覚化できる反復的な環境を提供することで、データ抽出と分析のタスクを簡素化します。これにより、使い慣れていない API を探索する場合に特に役立ちます。
Kotlin DataFrame ライブラリ と組み合わせて使用すると、Kotlin Notebook は API から JSON データに接続してフェッチできるだけでなく、包括的な分析と視覚化のためにこのデータを再形成するのにも役立ちます。
Kotlin Notebook の例については、GitHub の DataFrame の例 を参照してください。
開始する前に
-
最新バージョンの IntelliJ IDEA Ultimate をダウンロードしてインストールします。
-
IntelliJ IDEA に Kotlin Notebook plugin をインストールします。
または、IntelliJ IDEA 内の Settings | Plugins | Marketplace から Kotlin Notebook plugin にアクセスします。
-
File | New | Kotlin Notebook を選択して、新しい Kotlin Notebook を作成します。
-
Kotlin Notebook で、次のコマンドを実行して Kotlin DataFrame ライブラリをインポートします。
%use dataframe
API からデータをフェッチする
Kotlin DataFrame ライブラリを備えた Kotlin Notebook を使用して API からデータをフェッチするには、.read() 関数を使用します。これは、CSV や JSON などの ファイルからデータを取得する のと同様です。ただし、Web ベースのソースを扱う場合は、生の API データを構造化された形式に変換するために、追加のフォーマットが必要になる場合があります。
YouTube Data API からデータをフェッチする例を見てみましょう。
-
Kotlin Notebook ファイル (
.ipynb) を開きます。 -
データ操作タスクに不可欠な Kotlin DataFrame ライブラリをインポートします。 これは、コードセルで次のコマンドを実行することで行われます。
%use dataframe -
YouTube Data API へのリクエストを認証するために必要な API キーを新しいコードセルに安全に追加します。 API キーは、認証情報タブ から取得できます。
val apiKey = "YOUR-API_KEY" -
パスを文字列として受け取り、DataFrame の
.read()関数を使用して YouTube Data API からデータをフェッチするロード関数を作成します。fun load(path: String): AnyRow = DataRow.read("https://www.googleapis.com/youtube/v3/$path&key=$apiKey") -
フェッチされたデータを行に編成し、
nextPageTokenを使用して YouTube API のページネーションを処理します。 これにより、複数のページにわたってデータを収集できます。fun load(path: String, maxPages: Int): AnyFrame {
// Initializes a mutable list to store rows of data.
val rows = mutableListOf<AnyRow>()
// Sets the initial page path for data loading.
var pagePath = path
do {
// Loads data from the current page path.
val row = load(pagePath)
// Adds the loaded data as a row to the list.
rows.add(row)
// Retrieves the token for the next page, if available.
val next = row.getValueOrNull<String>("nextPageToken")
// Updates the page path for the next iteration, including the new token.
pagePath = path + "&pageToken=" + next
// Continues loading pages until there's no next page.
} while (next != null && rows.size < maxPages)
// Concatenates and returns all loaded rows as a DataFrame.
return rows.concat()
} -
前述の
load()関数を使用してデータをフェッチし、新しいコードセルに DataFrame を作成します。 この例では、最大 5 ページまで、ページあたり最大 50 件の結果で、Kotlin に関連するデータ (またはこの場合は動画) をフェッチします。 結果はdf変数に格納されます。val df = load("search?q=kotlin&maxResults=50&part=snippet", 5)
df -
最後に、DataFrame からアイテムを抽出して連結します。
val items = df.items.concat()
items
データをクリーンアップして絞り込む
データをクリーンアップして絞り込むことは、分析のためにデータセットを準備する上で重要なステップです。Kotlin DataFrame ライブラリ は、これらのタスクのための強力な機能を提供します。move、concat、select、parse、join などのメソッドは、データを整理および変換するのに役立ちます。
データが YouTube のデータ API を使用してすでにフェッチされている 例を見てみましょう。 目標は、詳細な分析の準備のために、データセットをクリーンアップして再構築することです。
-
データの再編成とクリーンアップから始めることができます。これには、明確にするために、特定の列を新しいヘッダーの下に移動し、不要な列を削除することが含まれます。
val videos = items.dropNulls { id.videoId }
.select { id.videoId named "id" and snippet }
.distinct()
videos -
クリーンアップされたデータから ID をチャンク化し、対応する動画の統計情報をロードします。これには、データをより小さなバッチに分割し、追加の詳細をフェッチすることが含まれます。
val statPages = clean.id.chunked(50).map {
val ids = it.joinToString("%2C")
load("videos?part=statistics&id=$ids")
}
statPages -
フェッチされた統計情報を連結し、関連する列を選択します。
val stats = statPages.items.concat().select { id and statistics.all() }.parse()
stats -
既存のクリーンアップされたデータを、新しくフェッチされた統計情報と結合します。これにより、2 つのデータセットが包括的な DataFrame にマージされます。
val joined = clean.join(stats)
joined
この例では、Kotlin DataFrame のさまざまな関数を使用してデータセットをクリーンアップ、再編成、および拡張する方法を示します。 各ステップは、データを絞り込み、詳細な分析 により適したものにするように設計されています。
Kotlin Notebook でデータを分析する
Kotlin DataFrame ライブラリ の関数を使用して、データを フェッチ し、クリーンアップおよび絞り込み が完了したら、次のステップは、この準備されたデータセットを分析して、意味のある洞察を抽出することです。
データを分類するための groupBy などのメソッド、要約統計 用の sum および maxBy、データを並べ替えるための sortBy が特に役立ちます。
これらのツールを使用すると、複雑なデータ分析タスクを効率的に実行できます。
groupBy を使用して動画をチャンネル別に分類し、sum を使用してカテゴリごとの合計再生回数を計算し、maxBy を使用して各グループの最新または最も視聴された動画を見つける例を見てみましょう。
-
参照を設定して、特定の列へのアクセスを簡素化します。
val view by column<Int>() -
groupByメソッドを使用して、channel列でデータをグループ化し、並べ替えます。val channels = joined.groupBy { channel }.sortByCount()
結果のテーブルでは、データをインタラクティブに調べることができます。チャンネルに対応する行の group フィールドをクリックすると、そのチャンネルの動画に関する詳細が表示されます。
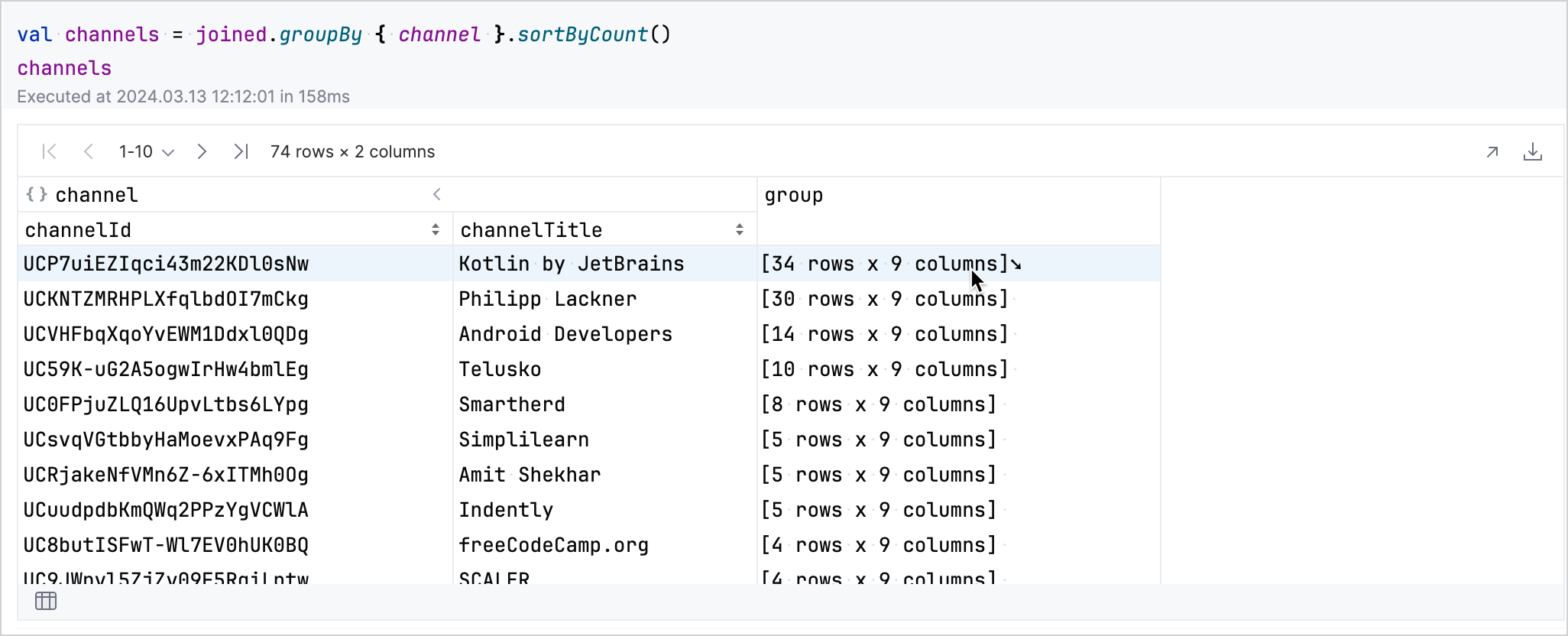
左下のテーブル アイコンをクリックして、グループ化されたデータセットに戻ることができます。
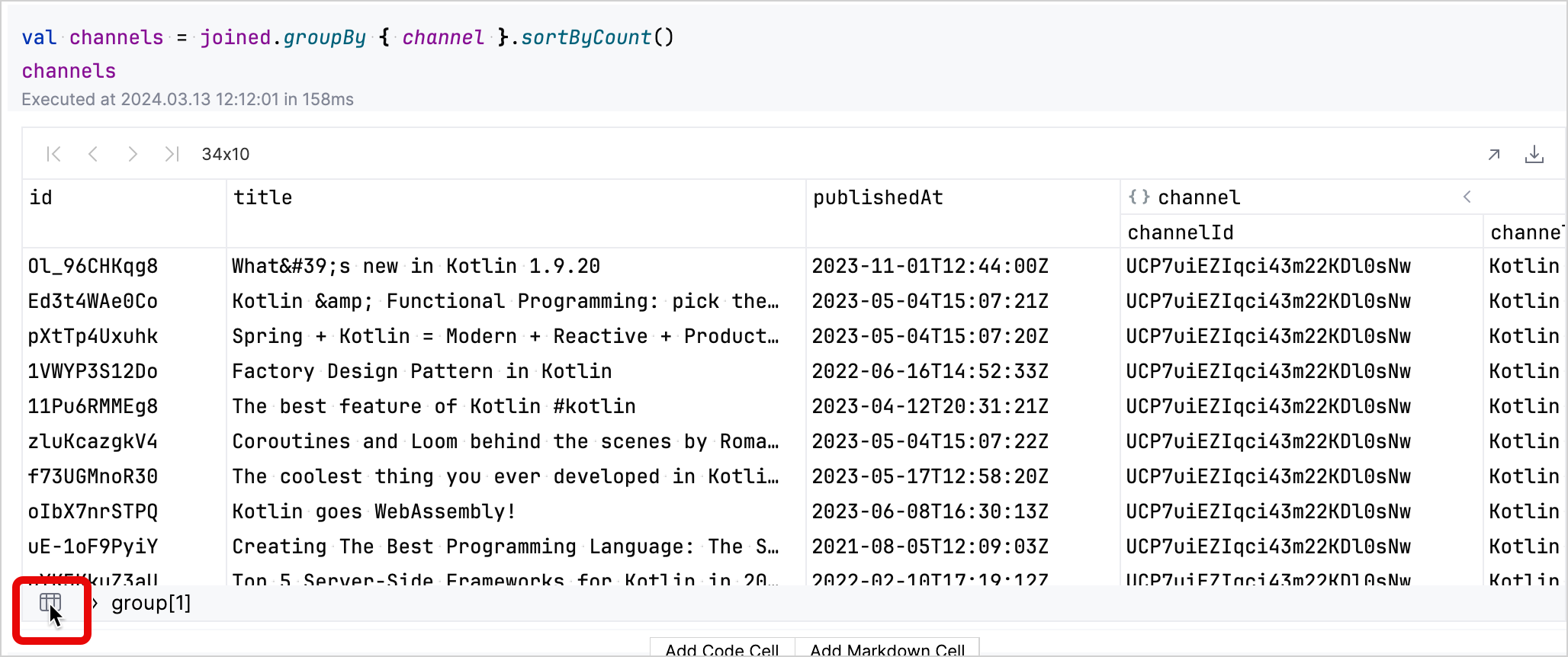
-
aggregate、sum、maxBy、およびflattenを使用して、各チャンネルの合計再生回数と、最新または最も視聴された動画の詳細を要約する DataFrame を作成します。val aggregated = channels.aggregate {
viewCount.sum() into view
val last = maxBy { publishedAt }
last.title into "last title"
last.publishedAt into "time"
last.viewCount into "viewCount"
// Sorts the DataFrame in descending order by view count and transform it into a flat structure.
}.sortByDesc(view).flatten()
aggregated
分析結果:
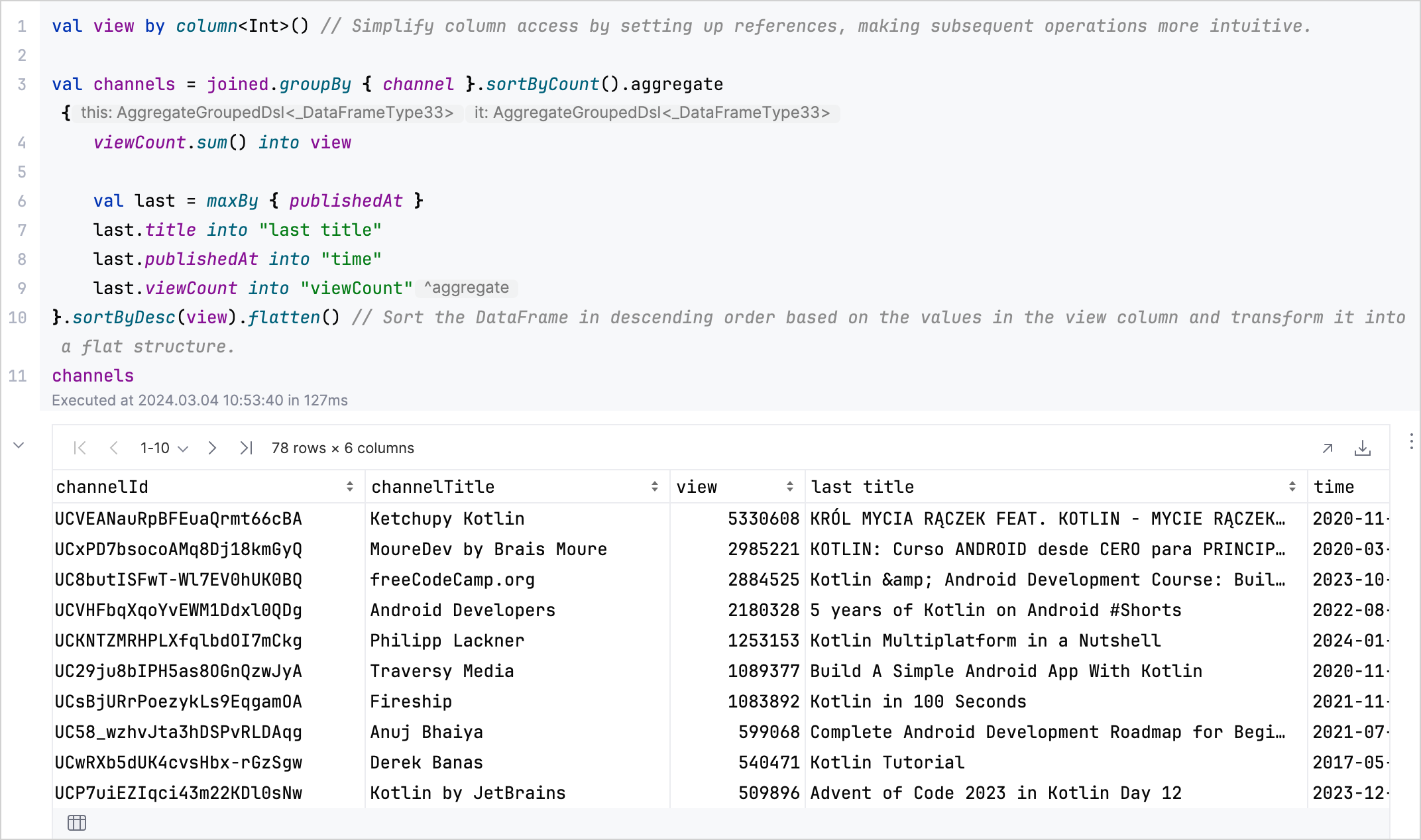
より高度な手法については、Kotlin DataFrame ドキュメント を参照してください。
次のステップ
- Kandy ライブラリ を使用したデータの視覚化について調べる
- Kotlin Notebook での Kandy を使用したデータの視覚化 で、データ視覚化に関する追加情報を見つける
- Kotlin でのデータサイエンスと分析に利用できるツールとリソースの包括的な概要については、データ分析用の Kotlin および Java ライブラリ を参照してください