從檔案中擷取資料
Kotlin Notebook 搭配 Kotlin DataFrame 函式庫,讓您能夠處理非結構化和結構化資料。這種結合提供了將非結構化資料(例如 TXT 檔案中的資料)轉換為結構化資料集的彈性。
對於資料轉換,您可以使用諸如 add、split、convert 和 parse 之類的方法。此外,此工具集還能夠從各種結構化檔案格式(包括 CSV、JSON、XLS、XLSX 和 Apache Arrow)中檢索和操作資料。
在本指南中,您可以透過多個範例了解如何檢索、精煉和處理資料。
開始之前
-
下載並安裝最新版本的 IntelliJ IDEA Ultimate。
-
在 IntelliJ IDEA 中安裝 Kotlin Notebook plugin。
或者,從 IntelliJ IDEA 內的 Settings(設定)| Plugins(外掛程式)| Marketplace(市集)存取 Kotlin Notebook 外掛程式。
-
選擇 File(檔案)| New(新增)| Kotlin Notebook 來建立新的 Kotlin Notebook。
-
在 Kotlin Notebook 中,執行以下命令導入 Kotlin DataFrame 函式庫:
%use dataframe
從檔案檢索資料
若要從 Kotlin Notebook 中的檔案檢索資料:
-
開啟您的 Kotlin Notebook 檔案 (
.ipynb)。 -
透過在筆記本開頭的程式碼儲存格中新增
%use dataframe來導入 Kotlin DataFrame 函式庫。請務必先執行包含
%use dataframe行的程式碼儲存格,再執行任何其他依賴 Kotlin DataFrame 函式庫的程式碼儲存格。 -
使用 Kotlin DataFrame 函式庫中的
.read()函式來檢索資料。例如,若要讀取 CSV 檔案,請使用:DataFrame.read("example.csv")。
.read() 函式會根據檔案副檔名和內容自動偵測輸入格式。您也可以新增其他引數來自訂函式,例如使用 delimiter = ';' 指定分隔符號。
如需其他檔案格式和各種讀取函式的完整概述,請參閱 Kotlin DataFrame 函式庫文件。
顯示資料
一旦您在筆記本中取得資料,就可以輕鬆地將其儲存在變數中,並透過在程式碼儲存格中執行以下程式碼來存取它:
val dfJson = DataFrame.read("jsonFile.json")
dfJson
此程式碼會顯示您選擇的檔案(例如 CSV、JSON、XLS、XLSX 或 Apache Arrow)中的資料。
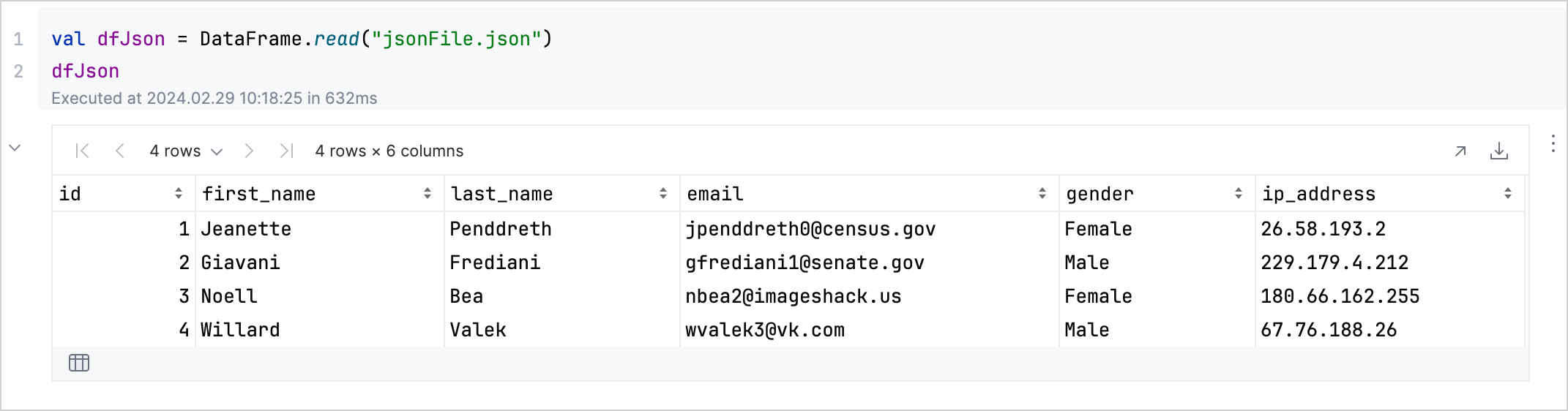
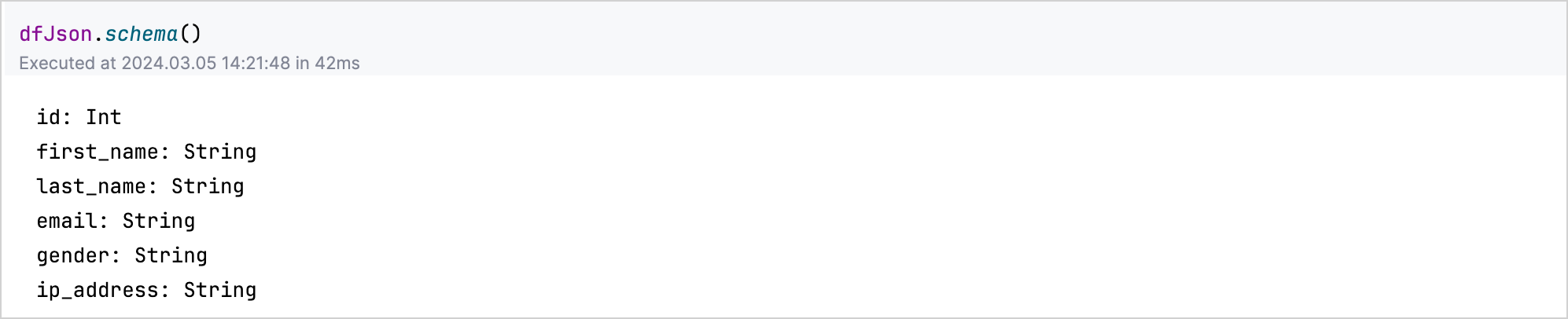
若要深入了解資料的結構或綱要(schema),請在您的 DataFrame 變數上套用 .schema() 函式。例如,dfJson.schema() 會列出 JSON 資料集中每欄的類型。
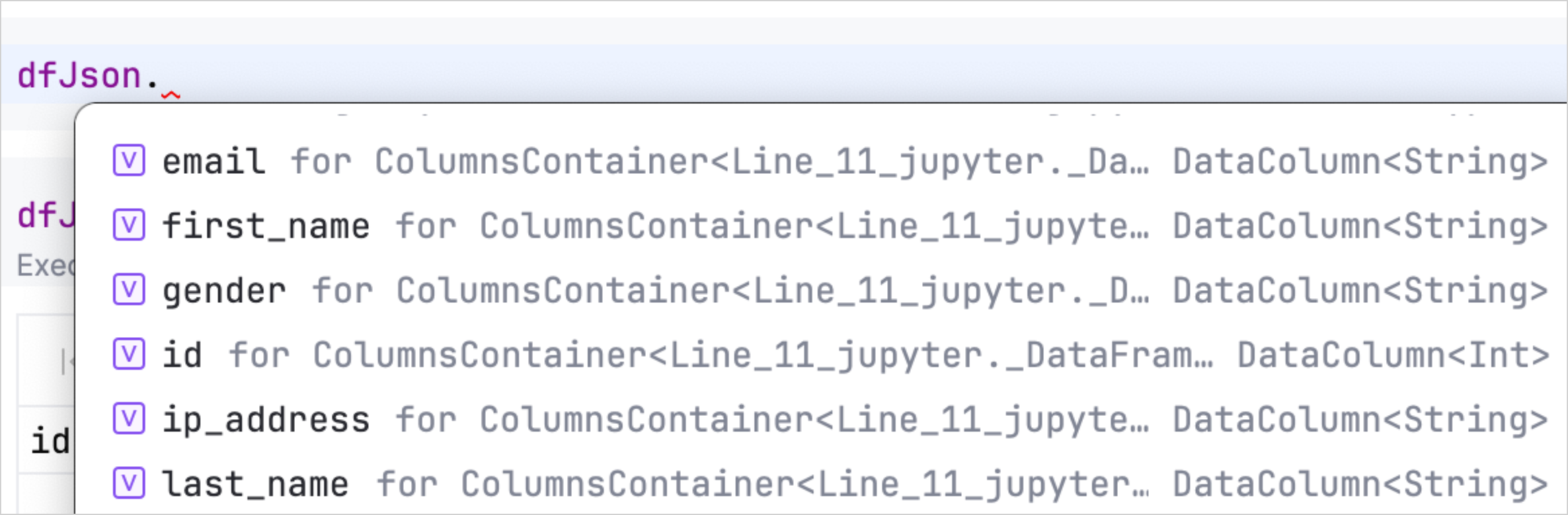
您也可以使用 Kotlin Notebook 中的自動完成功能來快速存取和操作 DataFrame 的屬性。載入資料後,只需輸入 DataFrame 變數,後跟一個點,即可查看可用欄及其類型的清單。
精煉資料
在 Kotlin DataFrame 函式庫中可用於精煉資料集的各種操作中,主要的範例包括 grouping、filtering、updating 和 adding new columns。這些函式對於資料分析至關重要,可讓您有效地組織、清理和轉換資料。
讓我們看一個範例,其中資料包括電影標題及其在同一個儲存格中對應的發布年份。目標是精煉此資料集,以便於分析:
-
使用
.read()函式將資料載入到筆記本中。此範例涉及從名為movies.csv的 CSV 檔案讀取資料,並建立名為movies的 DataFrame:val movies = DataFrame.read("movies.csv") -
使用正規表示式(regex)從電影標題中提取發布年份,並將其新增為新欄:
val moviesWithYear = movies
.add("year") {
"\\d{4}".toRegex()
.findAll(title)
.lastOrNull()
?.value
?.toInt()
?: -1
} -
透過從每個標題中移除發布年份來修改電影標題。這會清理標題以保持一致性:
val moviesTitle = moviesWithYear
.update("title") {
"\\s*\\(\\d{4}\\)\\s*$".toRegex().replace(title, "")
} -
使用
filter方法來關注特定資料。在本例中,資料集經過篩選,重點關注在 1996 年之後發布的電影:val moviesNew = moviesWithYear.filter { year >= 1996 }
moviesNew
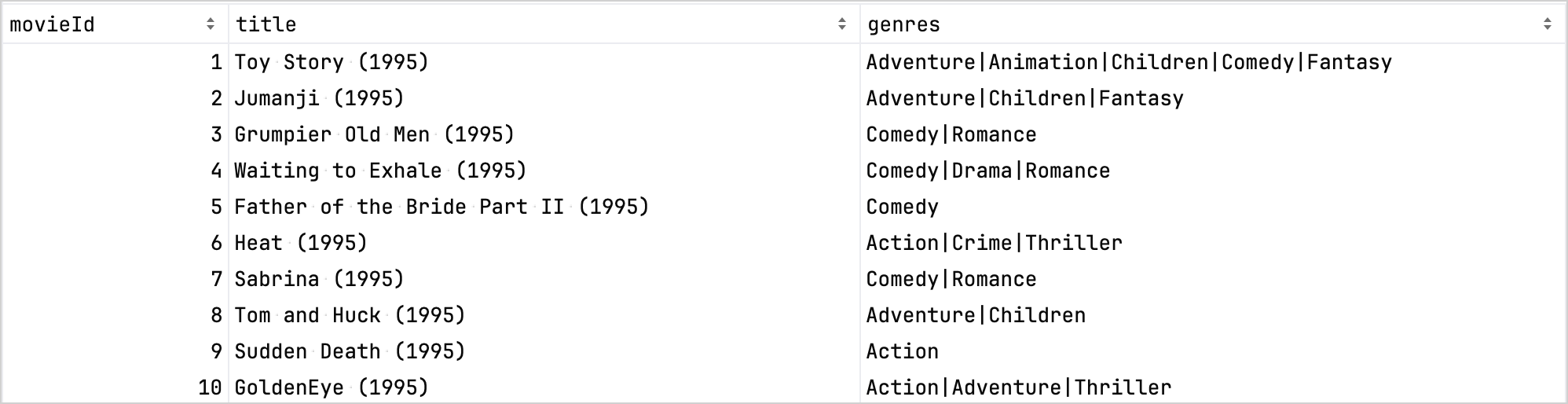
為了進行比較,以下是精煉之前的資料集:
精煉後的資料集:
這是一個實際的示範,說明如何使用 Kotlin DataFrame 函式庫的方法(如 add、update 和 filter)來有效地精煉和分析 Kotlin 中的資料。
如需其他使用案例和詳細範例,請參閱 Kotlin Dataframe 範例。
儲存 DataFrame
在使用 Kotlin DataFrame 函式庫精煉 Kotlin Notebook 中的資料之後,您可以輕鬆匯出處理後的資料。您可以為此使用各種 .write() 函式,這些函式支援以多種格式儲存,包括 CSV、JSON、XLS、XLSX、Apache Arrow,甚至 HTML 表格。這對於分享您的發現、建立報告或讓您的資料可用於進一步分析特別有用。
以下是如何篩選 DataFrame、移除欄、將精煉後的資料儲存到 JSON 檔案,以及在瀏覽器中開啟 HTML 表格的方法:
-
在 Kotlin Notebook 中,使用
.read()函式將名為movies.csv的檔案載入到名為moviesDf的 DataFrame 中:val moviesDf = DataFrame.read("movies.csv") -
使用
.filter方法篩選 DataFrame,使其僅包含屬於 "Action"(動作)類型的電影:val actionMoviesDf = moviesDf.filter { genres.equals("Action") } -
使用
.remove從 DataFrame 中移除movieId欄:val refinedMoviesDf = actionMoviesDf.remove { movieId }
refinedMoviesDf -
Kotlin DataFrame 函式庫提供了各種寫入函式,可用於以不同格式儲存資料。在本例中,使用
.writeJson()函式將修改後的movies.csv儲存為 JSON 檔案:refinedMoviesDf.writeJson("movies.json") -
使用
.toStandaloneHTML()函式將 DataFrame 轉換為獨立的 HTML 表格,並在您的預設網頁瀏覽器中開啟它:refinedMoviesDf.toStandaloneHTML(DisplayConfiguration(rowsLimit = null)).openInBrowser()
接下來做什麼
- 探索使用 Kandy 函式庫 進行資料視覺化
- 在 使用 Kandy 在 Kotlin Notebook 中進行資料視覺化 中尋找有關資料視覺化的其他資訊
- 如需 Kotlin 中可用於資料科學和分析的工具和資源的廣泛概述,請參閱 用於資料分析的 Kotlin 和 Java 函式庫