웹 소스 및 API에서 데이터 검색
Kotlin Notebook은 다양한 웹 소스 및 API로부터 데이터에 접근하고 조작할 수 있는 강력한 플랫폼을 제공합니다. 명확성을 위해 모든 단계를 시각화할 수 있는 반복적인 환경을 제공함으로써 데이터 추출 및 분석 작업을 단순화합니다. 이는 익숙하지 않은 API를 탐색할 때 특히 유용합니다.
Kotlin DataFrame 라이브러리와 함께 사용하면 Kotlin Notebook은 API에서 JSON 데이터를 연결하고 가져올 수 있을 뿐만 아니라 포괄적인 분석 및 시각화를 위해 이 데이터를 재구성하는 데 도움을 줍니다.
Kotlin Notebook 예제는 GitHub의 DataFrame 예제를 참조하십시오.
시작하기 전에
-
최신 버전의 IntelliJ IDEA Ultimate를 다운로드하여 설치합니다.
-
IntelliJ IDEA에 Kotlin Notebook plugin을 설치합니다.
또는 IntelliJ IDEA 내에서 Settings | Plugins | Marketplace에서 Kotlin Notebook plugin에 접근합니다.
-
File | New | Kotlin Notebook을 선택하여 새 Kotlin Notebook을 만듭니다.
-
Kotlin Notebook에서 다음 명령을 실행하여 Kotlin DataFrame 라이브러리를 가져옵니다.
%use dataframe
API에서 데이터 가져오기
Kotlin DataFrame 라이브러리와 함께 Kotlin Notebook을 사용하여 API에서 데이터를 가져오는 것은 .read() 함수를 통해 이루어지며, 이는 CSV 또는 JSON과 같은 파일에서 데이터를 검색하는 것과 유사합니다.
그러나 웹 기반 소스를 사용하는 경우 원시 API 데이터를 구조화된 형식으로 변환하기 위해 추가적인 형식이 필요할 수 있습니다.
YouTube Data API에서 데이터를 가져오는 예를 살펴보겠습니다.
-
Kotlin Notebook 파일(
.ipynb)을 엽니다. -
데이터 조작 작업에 필수적인 Kotlin DataFrame 라이브러리를 가져옵니다. 이는 코드 셀에서 다음 명령을 실행하여 수행됩니다.
%use dataframe -
YouTube Data API에 대한 요청을 인증하는 데 필요한 API 키를 새 코드 셀에 안전하게 추가합니다. credentials tab에서 API 키를 얻을 수 있습니다.
val apiKey = "YOUR-API_KEY" -
경로를 문자열로 가져오고 DataFrame의
.read()함수를 사용하여 YouTube Data API에서 데이터를 가져오는 로드 함수를 만듭니다.fun load(path: String): AnyRow = DataRow.read("https://www.googleapis.com/youtube/v3/$path&key=$apiKey") -
가져온 데이터를 행으로 구성하고
nextPageToken을 통해 YouTube API의 페이지네이션을 처리합니다. 이렇게 하면 여러 페이지에서 데이터를 수집할 수 있습니다.fun load(path: String, maxPages: Int): AnyFrame {
// 데이터 행을 저장하기 위한 변경 가능한 목록을 초기화합니다.
val rows = mutableListOf<AnyRow>()
// 데이터 로드를 위한 초기 페이지 경로를 설정합니다.
var pagePath = path
do {
// 현재 페이지 경로에서 데이터를 로드합니다.
val row = load(pagePath)
// 로드된 데이터를 목록에 행으로 추가합니다.
rows.add(row)
// 사용 가능한 경우 다음 페이지의 토큰을 검색합니다.
val next = row.getValueOrNull<String>("nextPageToken")
// 새 토큰을 포함하여 다음 반복을 위해 페이지 경로를 업데이트합니다.
pagePath = path + "&pageToken=" + next
// 다음 페이지가 없을 때까지 페이지 로드를 계속합니다.
} while (next != null && rows.size < maxPages)
// 로드된 모든 행을 연결하고 DataFrame으로 반환합니다.
return rows.concat()
} -
이전에 정의된
load()함수를 사용하여 데이터를 가져오고 새 코드 셀에서 DataFrame을 만듭니다. 이 예제에서는 Kotlin과 관련된 데이터를 가져오거나 이 경우 최대 페이지 5개까지 페이지당 최대 50개의 결과가 있는 비디오를 가져옵니다. 결과는df변수에 저장됩니다.val df = load("search?q=kotlin&maxResults=50&part=snippet", 5)
df -
마지막으로 DataFrame에서 항목을 추출하고 연결합니다.
val items = df.items.concat()
items
데이터 정리 및 개선
데이터를 정리하고 개선하는 것은 분석을 위해 데이터 세트를 준비하는 데 중요한 단계입니다. Kotlin DataFrame 라이브러리는 이러한 작업을 위한 강력한 기능을 제공합니다. move,
concat, select,
parse 및 join과 같은 메서드는 데이터를 구성하고 변환하는 데 매우 중요합니다.
데이터가 이미 YouTube의 데이터 API를 사용하여 가져온 예를 살펴보겠습니다. 목표는 심층 분석을 위해 데이터 세트를 정리하고 재구성하는 것입니다.
-
데이터를 재구성하고 정리하는 것으로 시작할 수 있습니다. 여기에는 명확성을 위해 특정 열을 새 헤더 아래로 이동하고 불필요한 열을 제거하는 작업이 포함됩니다.
val videos = items.dropNulls { id.videoId }
.select { id.videoId named "id" and snippet }
.distinct()
videos -
정리된 데이터에서 ID를 청크하고 해당 비디오 통계를 로드합니다. 여기에는 데이터를 더 작은 배치로 나누고 추가 세부 정보를 가져오는 작업이 포함됩니다.
val statPages = clean.id.chunked(50).map {
val ids = it.joinToString("%2C")
load("videos?part=statistics&id=$ids")
}
statPages -
가져온 통계를 연결하고 관련 열을 선택합니다.
val stats = statPages.items.concat().select { id and statistics.all() }.parse()
stats -
기존 정리된 데이터를 새로 가져온 통계와 조인합니다. 이렇게 하면 두 세트의 데이터가 포괄적인 DataFrame으로 병합됩니다.
val joined = clean.join(stats)
joined
이 예제에서는 Kotlin DataFrame의 다양한 함수를 사용하여 데이터 세트를 정리, 재구성 및 개선하는 방법을 보여줍니다. 각 단계는 데이터를 개선하여 심층 분석에 더 적합하도록 설계되었습니다.
Kotlin Notebook에서 데이터 분석
Kotlin DataFrame 라이브러리의 함수를 사용하여 데이터를 성공적으로 가져오고 정리하고 개선한 후 다음 단계는 이 준비된 데이터 세트를 분석하여 의미 있는 통찰력을 추출하는 것입니다.
데이터를 분류하기 위한 groupBy,
요약 통계를 위한 sum 및 maxBy, 데이터를 정렬하기 위한 sortBy과 같은 메서드가 특히 유용합니다. 이러한 도구를 사용하면 복잡한 데이터 분석 작업을 효율적으로 수행할 수 있습니다.
groupBy를 사용하여 채널별로 비디오를 분류하고, sum을 사용하여 카테고리별 총 조회수를 계산하고, maxBy를 사용하여 각 그룹에서 최신 또는 가장 많이 본 비디오를 찾는 예를 살펴보겠습니다.
-
참조를 설정하여 특정 열에 대한 접근을 단순화합니다.
val view by column<Int>() -
groupBy메서드를 사용하여 데이터를channel열로 그룹화하고 정렬합니다.val channels = joined.groupBy { channel }.sortByCount()
결과 테이블에서 데이터를 대화식으로 탐색할 수 있습니다. 채널에 해당하는 행의 group 필드를 클릭하면 해당 채널의 비디오에 대한 자세한 내용이 표시되도록 해당 행이 확장됩니다.
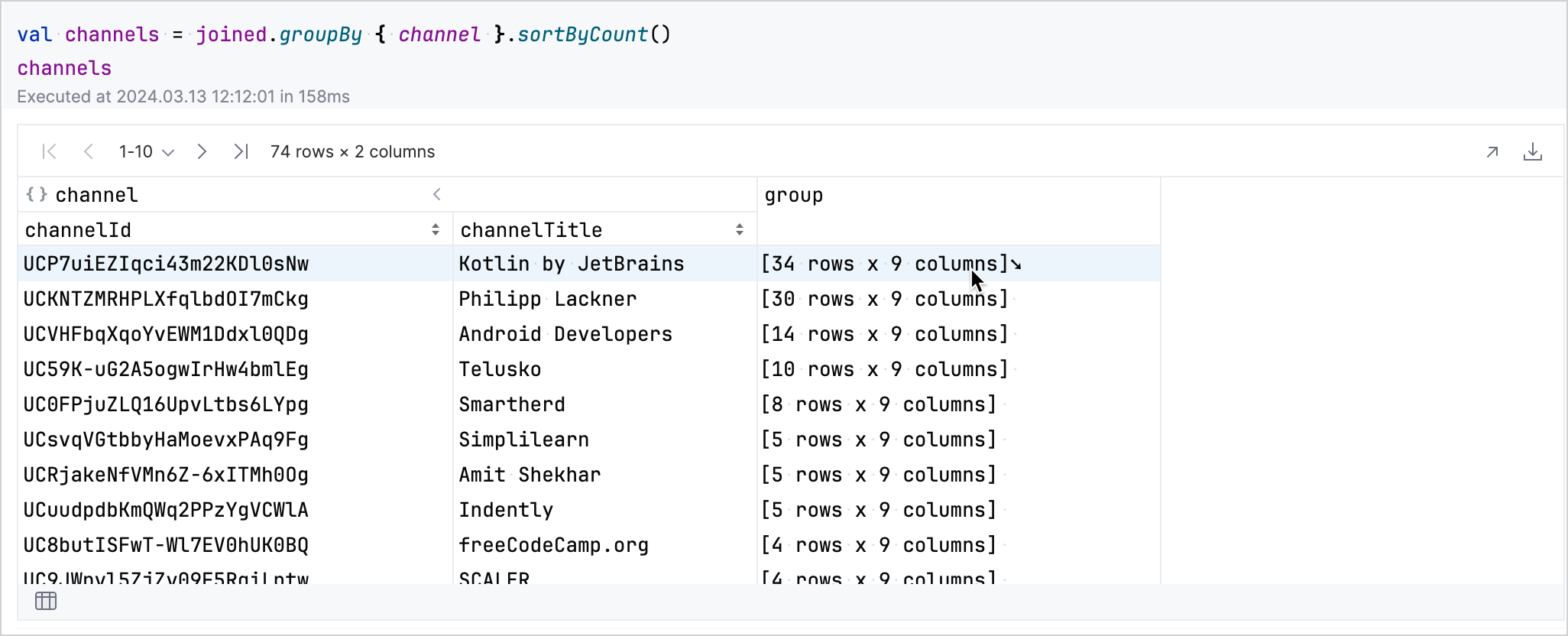
왼쪽 하단의 테이블 아이콘을 클릭하여 그룹화된 데이터 세트로 돌아갈 수 있습니다.
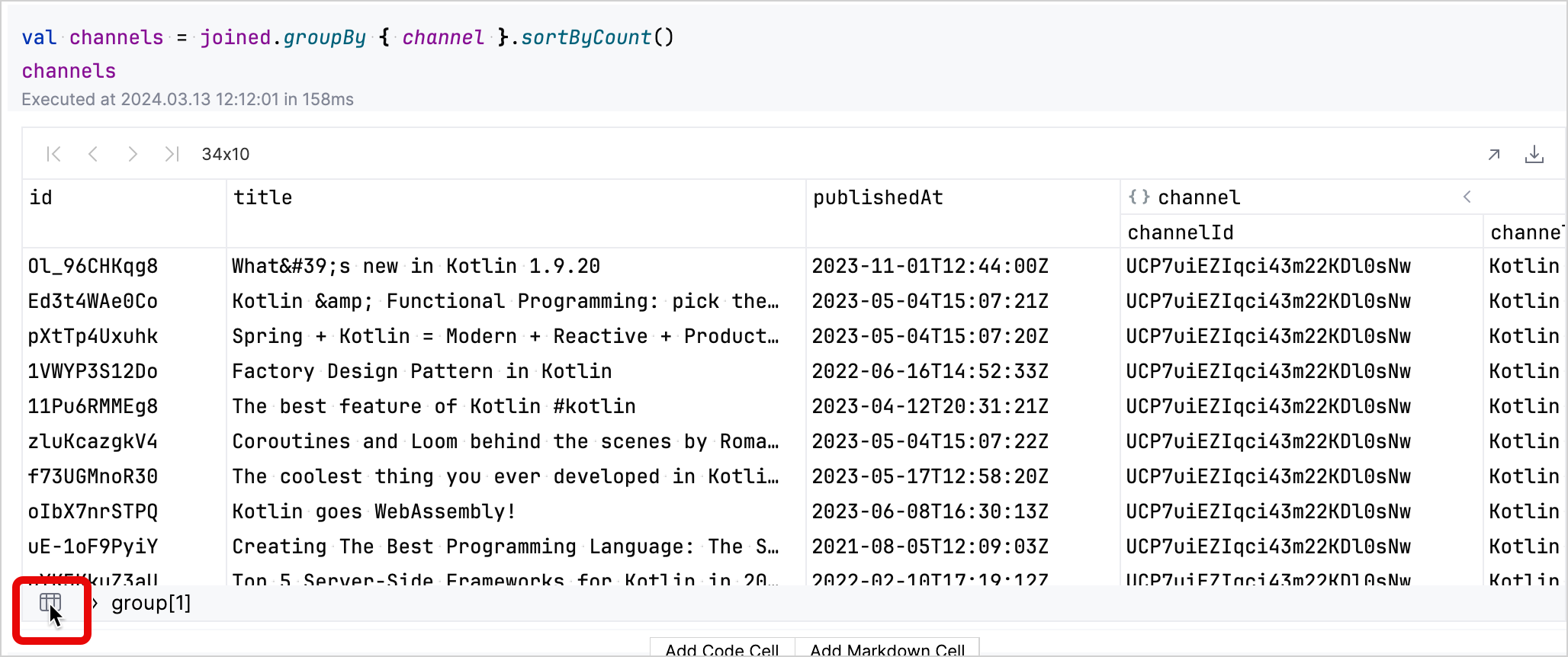
-
aggregate,sum,maxBy및flatten을 사용하여 각 채널의 총 조회수와 최신 또는 가장 많이 본 비디오의 세부 정보를 요약하는 DataFrame을 만듭니다.val aggregated = channels.aggregate {
viewCount.sum() into view
val last = maxBy { publishedAt }
last.title into "last title"
last.publishedAt into "time"
last.viewCount into "viewCount"
// 조회수별로 내림차순으로 DataFrame을 정렬하고 평면 구조로 변환합니다.
}.sortByDesc(view).flatten()
aggregated
분석 결과:
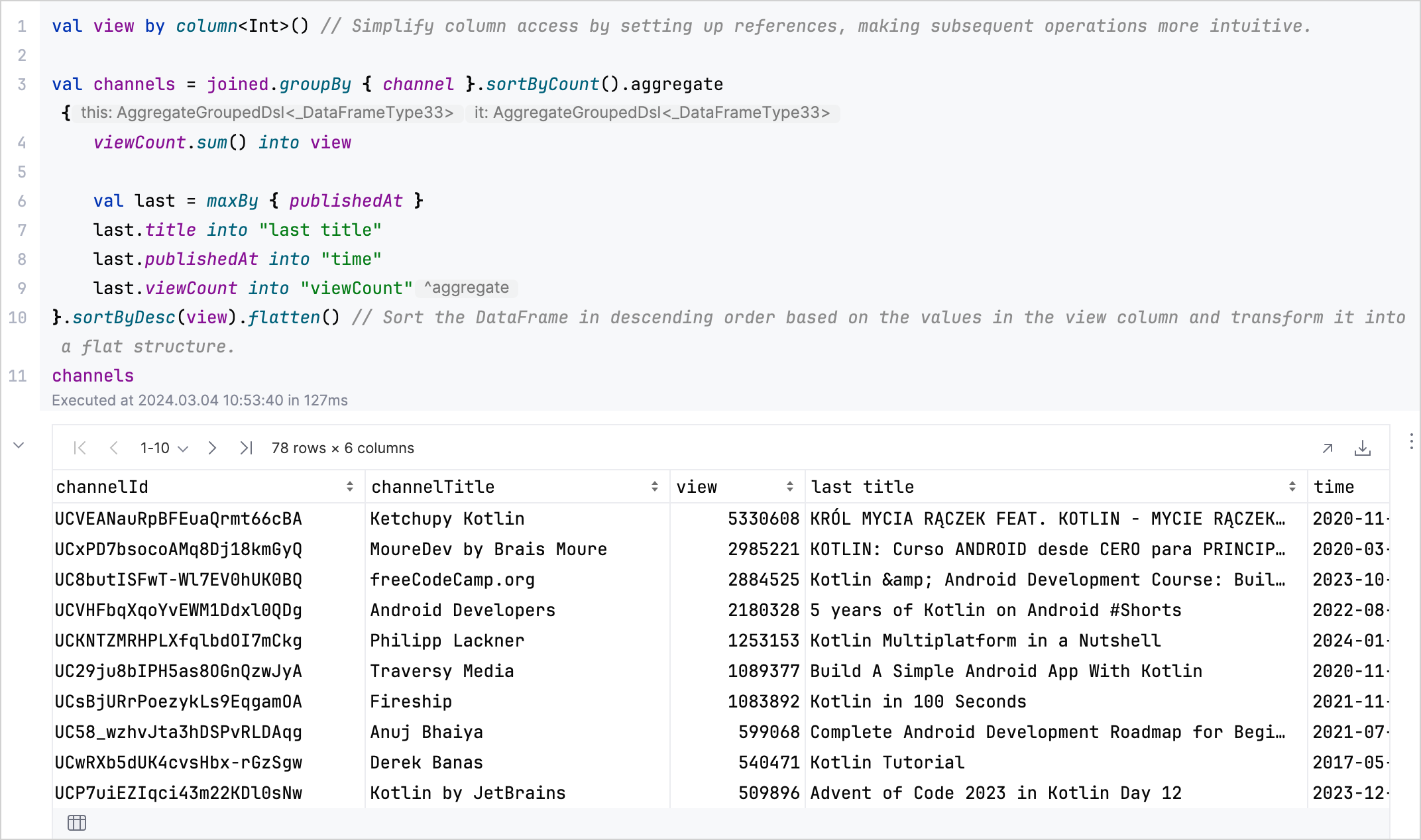
더욱 발전된 기술은 Kotlin DataFrame 문서를 참조하십시오.
다음 단계
- Kandy 라이브러리를 사용하여 데이터 시각화를 탐색합니다.
- Kotlin Notebook에서 Kandy를 사용한 데이터 시각화에서 데이터 시각화에 대한 추가 정보를 찾습니다.
- Kotlin에서 데이터 과학 및 분석에 사용할 수 있는 도구 및 리소스에 대한 광범위한 개요는 데이터 분석을 위한 Kotlin 및 Java 라이브러리를 참조하십시오.